Avec l'entrée en vigueur du Règlement Général européen sur la Protection des Données (RGPD) le 25 mai 2018, les entreprises ont été mises dans l'obligation non seulement d'être responsables dans le traitement des données personnelles, mais aussi de les protéger tout particulièrement.
Il fait la distinction entre les données à caractère personnel qui permettent de tirer des conclusions sur des personnes existant réellement et les autres données dont le traitement ainsi que le stockage garantissent la confidentialité des données. Même si le RGPD ne donne pas de directives concernant la protection des données, il énumère toutefois des procédures à mettre en œuvre. Il s'agit entre autres de l'anonymisation et de la pseudonymisation.
Mais que signifient exactement ces termes et quelles sont les différences entre les différentes procédures ? Cet article de blog se penche sur ces mystères et tente d'éclaircir la situation.
Anonymisation - qu'est-ce que cela signifie exactement ?
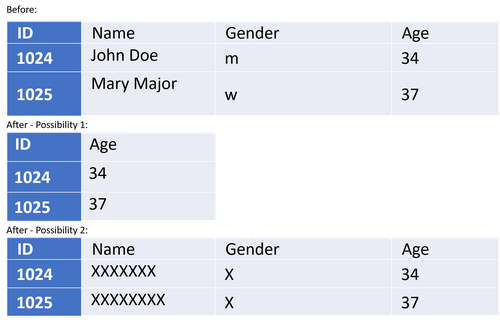
L'anonymisation consiste à supprimer certaines caractéristiques qui pourraient permettre d'identifier une personne donnée ou de tirer des conclusions sur cette personne. Pour que les données ne puissent plus être attribuées à cette personne, certaines caractéristiques, comme le nom, sont supprimées. Si des caractéristiques n'apparaissent que pour une seule personne dans la base de données, elles doivent également être supprimées, ou au moins généralisées. Il convient également de s'assurer qu'une combinaison de différentes caractéristiques ne permette pas d'identifier une personne en particulier.
Comment se distingue la pseudonymisation de l'anonymisation ?
Le RGPD définit la pseudonymisation à l'article 4 comme étant :
"le traitement de données à caractère personnel de telle manière que ces données ne puissent plus être attribuées à une personne concernée spécifique sans avoir recours à des informations supplémentaires, à condition que ces informations supplémentaires soient conservées séparément et soumises à des mesures techniques et organisationnelles visant à garantir que les données à caractère personnel ne sont pas attribuées à une personne physique identifiée ou identifiable" (source).
Cela signifie que grâce au processus de pseudonymisation, les données ne peuvent plus être attribuées à une personne spécifique sans informations supplémentaires. Les informations nécessaires à l'attribution ne sont pas disponibles, car elles sont conservées séparément et protégées contre tout accès par des mesures techniques et organisationnelles. La procédure donne uniquement aux personnes autorisées le droit de rétablir ce lien.
Libelle IT Group a développé ici, avec Libelle DataMasking, une solution pour l'anonymisation et la pseudonymisation nécessaires. La solution a été conçue pour produire des données anonymisées et logiquement cohérentes sur les systèmes de développement, de test et de qualité sur toutes les plateformes.
Les méthodes d'anonymisation utilisées fournissent des valeurs réalistes et logiquement correctes qui permettent de décrire des cas d'affaires pertinents et de les tester de manière pertinente de bout en bout. En outre, les développeurs et les utilisateurs disposent d'une base de données "propre" qui leur permet de ne pas se soucier de la protection des données.
Article recommandé
28 septembre 2022Glossaire informatique de Libelle, partie 17 : Qu'est-ce que l'automatisation des processus informatiques ?