Libelle DataMasking
Libelle DataMasking permet d’obtenir des données anonymisées et cohérentes tant pour le développement que pour le test des applications et des processus métiers. Elles restent facilement manipulables que ce soit sur SAP® ou tout autre environnement. Les méthodes d’anonymisation utilisées sont conformes au RGPD
Elles fournissent des valeurs réalistes qui respectent la logique des données remplacées. Les développeurs peuvent ainsi accéder facilement aux systèmes de développement ou de test et former les participants. De plus, l’analyse des experts reste pertinente malgré l’anonymat des données.
Vous pouvez essayer la version démo de Libelle DataMasking par vous-même, gratuitement & à tout moment
Comment Libelle DataMasking apermis l’anonymisation des données d’un acteur du secteur bancaire. Plus d’unmilliard de données anonymisés en toute cohérence, logique et sécurité en moinsde six heures.
Libelle DataMasking fonctionne sur les bases de données. Cela permet d’anonymiser jusqu’à 200 000 entrées de données par seconde. Si besoin, les tables peuvent être anonymisées en parallèle.
Libelle DataMasking fournit en standard plus de 40 algorithmes d’anonymisation et une base de données de référence avec des valeurs cibles définies. Cependant, la solution est personnalisable en fonction de vos besoins.
Nous transformons des données en valeurs réalistes et cohérentes. Vous pouvez ainsi tester, former et évaluer de manière réaliste vos systèmes non productifs – sans référence personnelle concrète.
Libelle DataMasking peut accéder aux bases de données communes. La solution peut être utilisée pour des systèmes individuels ou des paysages complets. Les bases de données des différents environnements sont également anonymisées entre systèmes.
Pour répondre aux besoins de nos clients, nous nous développons en permanence, et ce même à travers Libelle DataMasking. Pour notre dernière version nous avons ajouté une phase de test avant les étapes de travail réelles. Cela simule une anonymisation complète jusqu’aux modifications réelles des données. Cela vous permet de tester en amont tous les processus critiques. De plus, la solution corrige les erreurs avant de débuter le processus d’anonymisation qui se lancera automatiquement.
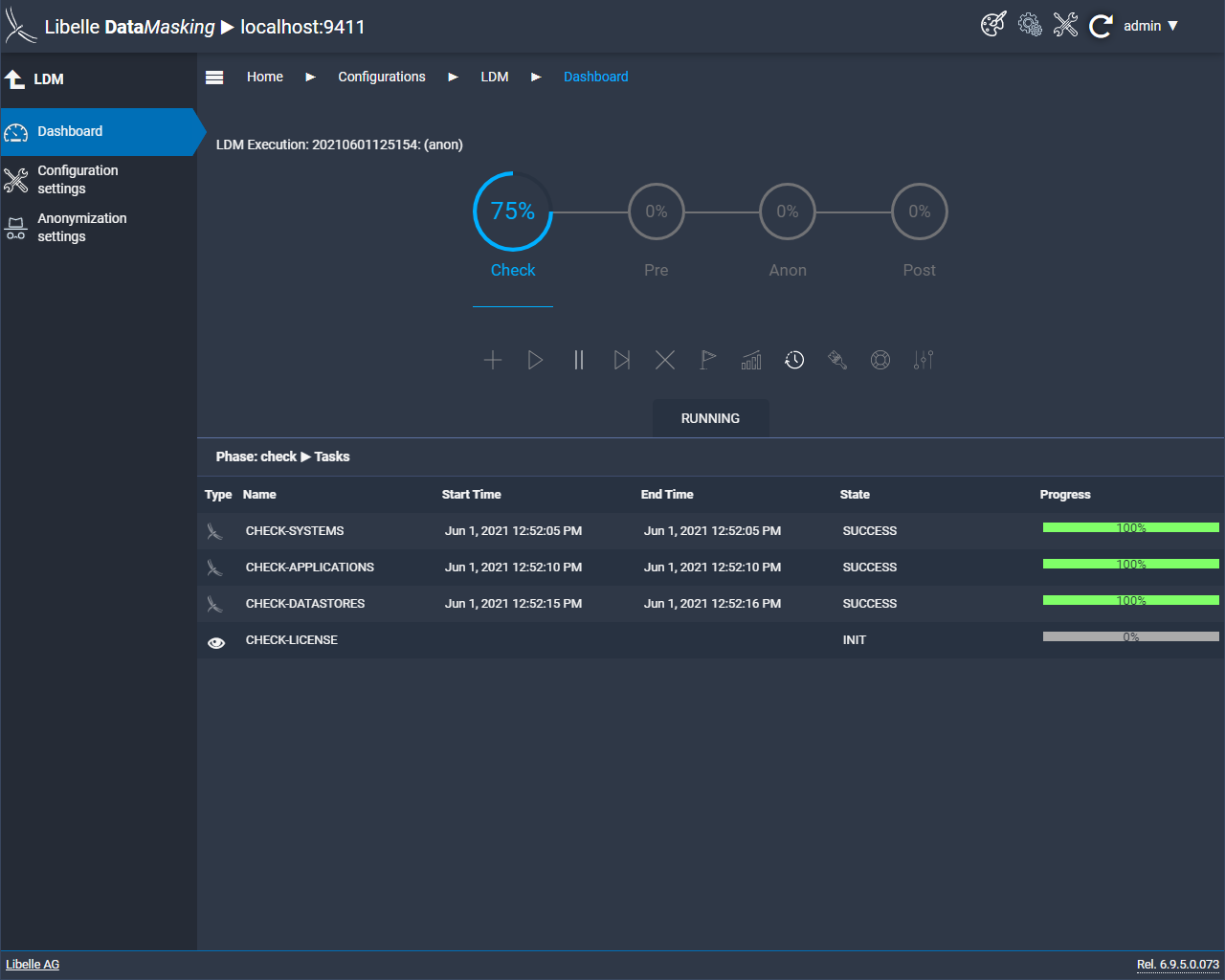
Dans la phase de contrôle, Libelle DataMasking vérifie l’infrastructure de votre informatique et la disponibilité du système cible. En particulier pour les environnements SAP, il permet de s’assurer que le système n’est pas en production. Cette opération est entièrement automatique et constitue une étape importante pour tirer pleinement parti du Libelle DataMasking. Les erreurs ou les champs qui n’ont pas été reconnus peuvent alors être facilement corrigés.
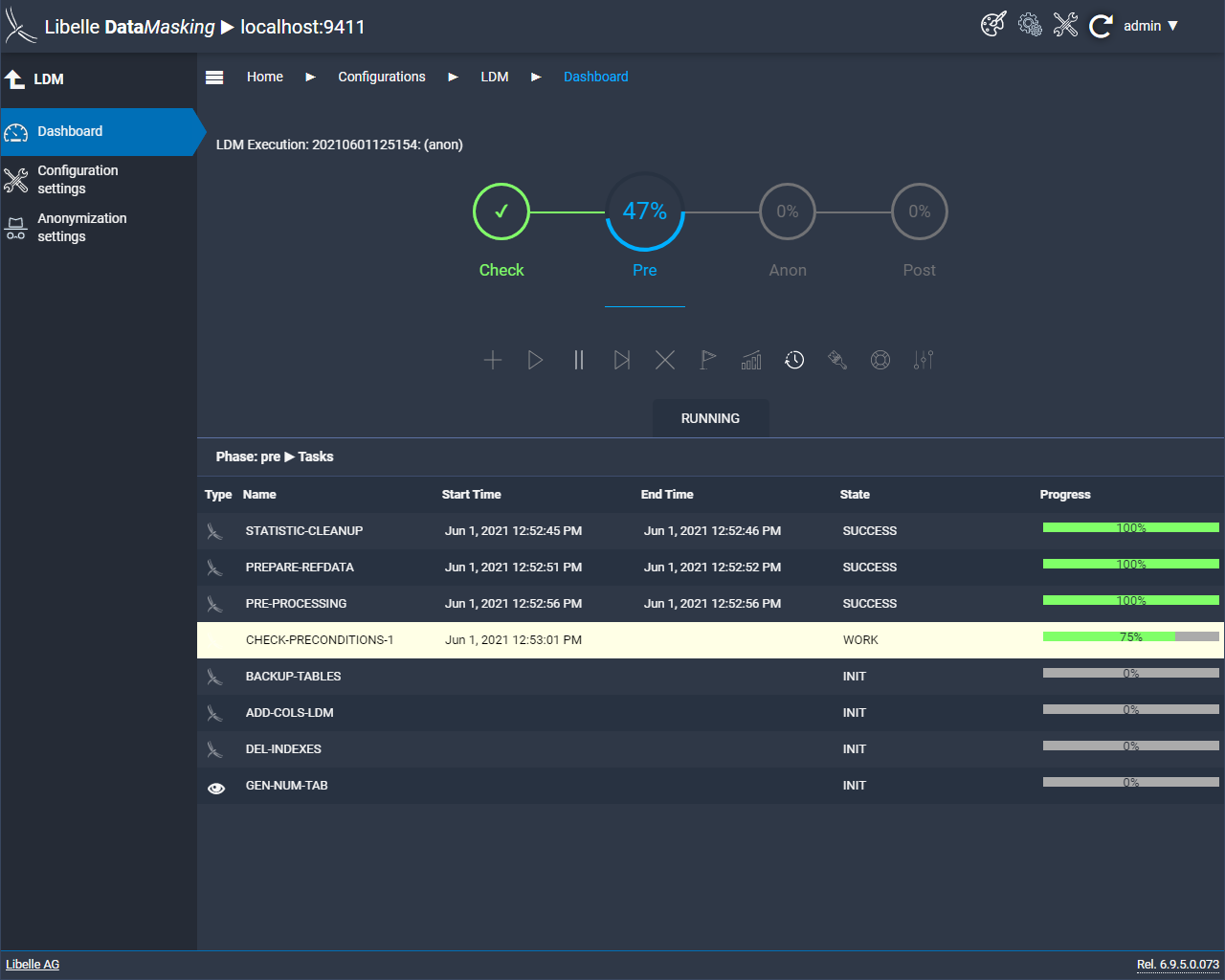
Après l’étape test, on passe au pre-processing. C’est à ce moment que sont fournis les fichiers de référence et que sont générées les clés d’anonymisation. Si nécessaire, vous pouvez également y créer des tableaux de sauvegarde. Ils pourront toujours servir si la première anonymisation ne s’est pas réalisée selon vos souhaits.

Durant cette phase, les algorithmes d’anonymisation fournis et définis individuellement sont appliqués. Les données du système cible non productif sont analysées et anonymisées par les algorithmes. Le résultat est réaliste et conformes au RGPD.
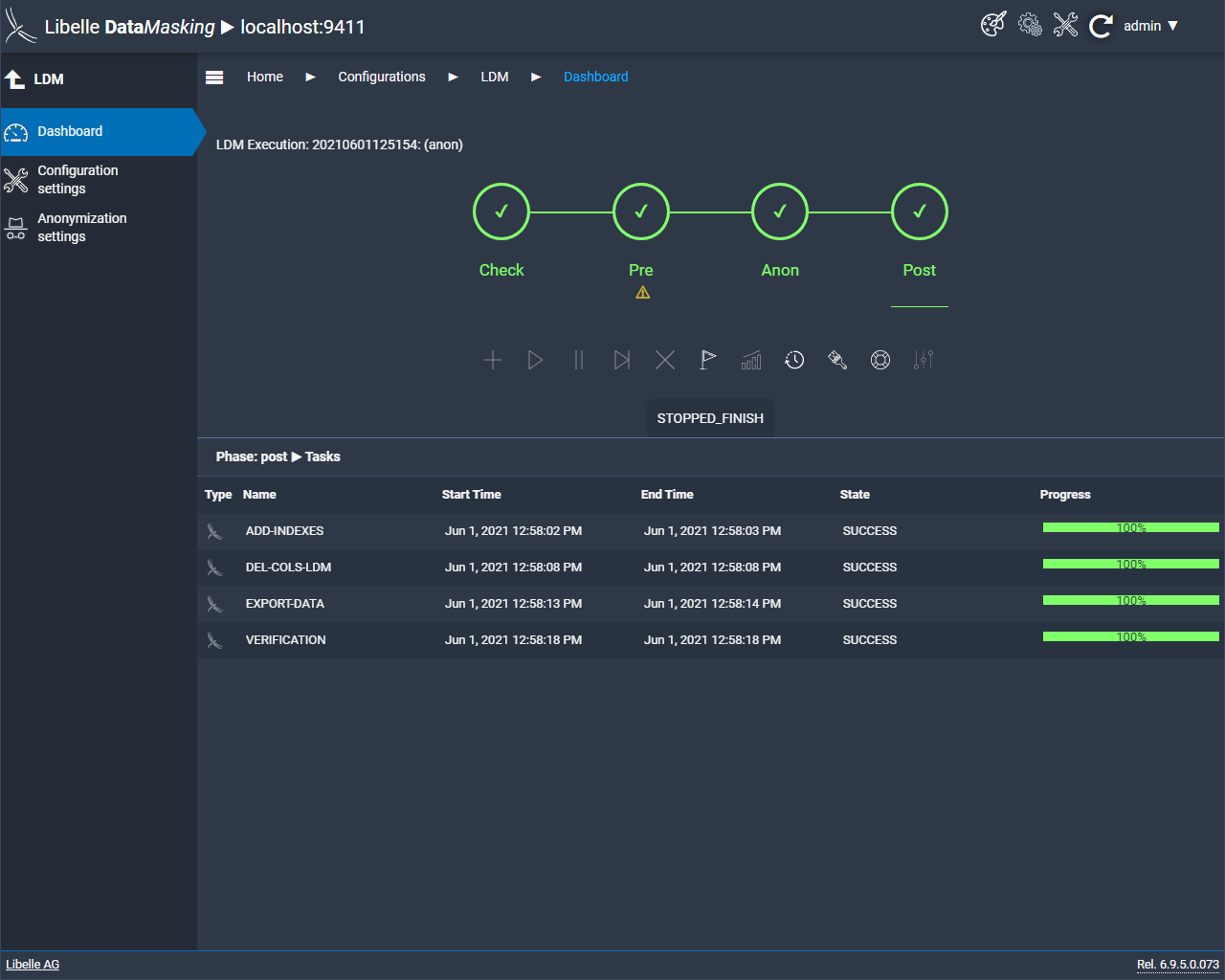
Durant cette dernière étape, on vérifie la cohérence des données. C’est une phase primordiale pour obtenir un résultat optimal. Afin d’avoir un aperçu complet de l’anonymisation, Libelle DataMasking fournit un rapport complet contenant des informations pertinentes.
Libelle DataMasking est prêt pour le cloud et peut être déployé en tant qu’image machine sur les fournisseurs suivants :
En savoir plus sur la façon de déployer Libelle DataMasking dans le cloud
