L'objectif du masquage de données est de masquer les données considérées comme sensibles dans les systèmes non productifs afin de réduire les risques et de répondre aux exigences légales et de conformité. Les données sont physiquement remplacées par des données non sensibles. Celles-ci suivent des modèles définis afin de conserver la structure et la nature des données d'origine, mais sans risque d'exposition réelle des données. Cette méthode s'applique aux systèmes d'aide à la production pour les tests et le développement ou aux entrepôts de données et aux systèmes d'analyse.
Le masquage - étape par étape
Le masquage des données se fait de manière ad hoc. En général, lorsqu'un système de test est créé ou mis à jour avec des données de production non masquées. En supposant qu'une base de données soit masquée, on pourrait envisager un flux de travail simplifié du masquage en trois étapes :
Lecture des données de la base de données
Masquage des données
Réécrire les données masquées dans la base de données.
Pour le masquage de quelques milliers d'enregistrements, les performances ne posent pas de problème. Cependant, la plupart des projets de masquage nécessitent le masquage de plusieurs millions, voire de milliards de lignes de données sensibles. Au-delà de quelques millions d'enregistrements, l'exécution séquentielle des opérations de lecture, de masquage et d'écriture pour chaque ligne peut prendre des jours, voire des semaines.
Le masquage des données fonctionne efficacement avec la parallélisation et le multithreading
Libelle IT Group a mis en œuvre une architecture multithreading intelligente afin d'augmenter les performances à un maximum absolu. Les bases de données sont expressément conçues pour le traitement parallèle de millions d'opérations de lecture et d'écriture. Envoyer des opérations de lecture et d'écriture séquentielles à une base de données, c'est comme si votre détaillant en ligne préféré exploitait un seul camion qui ne transporte qu'une caisse à la fois entre les destinations - un non-sens. Au contraire, l'infrastructure logistique peut gérer des milliers de véhicules, et chaque véhicule peut transporter des centaines de caisses. Il en va de même pour le processus de masquage des données.
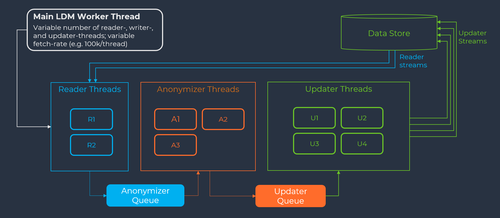
L'architecture multi-threading de Libelle DataMasking
Le diagramme suivant montre comment Libelle a développé et exploite l'architecture multithreading. Elle est intégrée dans l'architecture de la plate-forme Libelle sur laquelle fonctionne le serveur Libelle DataMasking.
Au début de chaque exécution, l'administrateur peut définir le taux d'appel. Par défaut, le taux d'extraction est réglé sur 100 000 enregistrements à la fois, un enregistrement représentant typiquement une ligne dans une base de données. Cela signifie que chaque thread contient 100k lignes.
La configuration de masquage contient déjà la table et les champs qui doivent être masqués. Avec ces informations, les threads de lecture commencent à lire chacun 100k enregistrements de la base de données. Un bon point de départ est généralement deux threads de lecture (2RT) qui lisent les données, les font glisser dans le serveur de masquage et placent les données lues dans la file d'attente de l'anonymiseur.
Dès que les données sont arrivées dans la file d'attente de l'anonymiseur, elles sont masquées par le serveur de masquage à l'aide du ou des algorithmes respectifs, chaque thread ayant toujours 100k enregistrements de données. Au cours de ce processus, les noms sont modifiés, les numéros sont regénérés, les adresses sont modifiées, etc. L'anonymisation peut prendre plus de temps que la lecture, de sorte que dans ce cas, trois threads d'anonymisation (3AT) constituent un bon point de départ.
Une fois que chaque thread de la file d'attente d'anonymisation est terminé, les données arrivent dans la file d'attente de mise à jour. Ici, les données sont réécrites dans la base de données, toujours avec 100k enregistrements pour chaque thread. L'écriture dans la base de données peut être plus coûteuse en termes de ressources, de sorte que quatre threads de mise à jour (4UT) constituent un bon point de départ.
La configuration standard de 2RT / 3AT / 4UT peut être adaptée à tout nombre souhaité sur la base des exigences individuelles de chaque magasin de données.
Performance extrême
Le masquage doit être terminé le plus rapidement possible, car les utilisateurs finaux ont besoin de leur système d'analyse ou de test le plus rapidement possible. Le multi-threading présente un avantage étonnant : la charge de travail peut être répartie sur plusieurs CPU et, selon la base de données, parfois même sur plusieurs nœuds de base de données. Il est ainsi possible d'atteindre une vitesse de 100 000 mises à jour ou plus par seconde.
Pensez à un environnement cloud dans lequel vous pouvez déplacer temporairement la charge de travail sur des machines plus grandes. Pourquoi ne pas déplacer temporairement l'environnement de test sur une bête de somme avec 512 vCPU / 2 To de mémoire dans le cloud public de votre choix, exécuter le masquage, puis revenir à votre serveur de test plus petit ?
Plus d'informations sur Libelle DataMasking
Libelle IT Group a développé Libelle DataMasking, une solution pour l'anonymisation et la pseudonymisation nécessaires. La solution a été conçue pour produire des données anonymisées et logiquement cohérentes sur les systèmes de développement, de test et de qualité sur toutes les plateformes.
Les méthodes d'anonymisation utilisées fournissent des valeurs réalistes et logiquement correctes qui permettent de décrire des cas d'affaires pertinents et de les tester de manière pertinente de bout en bout. En outre, les développeurs et les utilisateurs disposent d'une base de données "propre" qui leur permet de ne pas se soucier de la protection des données.
Article recommandé
15 septembre 2022Pourquoi les copies de système et l'anonymisation des données vont-elles de pair ?