L'informatique sans serveur à l'exemple du Cloud IBM
Le secteur informatique "Cloud" est en croissance constante et offre aux clients différents services et donc un éventail diversifié de possibilités. Dans l’article "Qu'est-ce que l'informatique sans serveur ?", nous avons décrit les concepts de l'informatique sans serveur et ses possibilités. De plus, nous aborderons les avantages et les inconvénients de l'utilisation de ces services. Nous avons également abordé plus en détail le sujet d'AWS Lambda. L'article suivant examine comment l'informatique sans serveur fonctionne dans l'environnement IBM Cloud.
Quelles sont les capacités de l'informatique sans serveur offertes par IBM Cloud ?
Le Cloud IBM propose une solution de fonction en tant que service (FaaS) appelée IBM Cloud™ Functions. Celle-ci vous permet d'exécuter une logique applicative en réponse à des événements ou des appels directs à des applications Web ou mobiles via HTTP. Le tout sans utiliser d'infrastructure de serveur. Cloud Functions prend en charge la gestion du système, comme la gestion de la disponibilité et la maintenance. Ceci permettra aux développeurs de se concentrer sur l’écriture de la logique applicative. (Source)
Comment démarrer avec IBM Cloud Functions
Le développement peut commencer de deux façons :
- Interface utilisateur de Cloud Functions
- L'interface de ligne de commande (CLI) de Cloud Functions, qui offre un meilleur contrôle sur votre déploiement et vos opérations.
Les deux méthodes produisent les mêmes résultats. Les étapes de la procédure sont similaires pour les deux chemins et sont listées ci-dessous comme un guide pas à pas. (Source)
- Étape 1 : Créer un compte IBM Cloud et se connecter
- Étape 2 : Naviguer vers le tableau de bord Cloud Functions
- Étape 3 : Sélectionnez un espace de nom (obligatoire)
- Étape 4 : Cliquez sur Start Creating > Quickstart Templates et sélectionnez le modèle Hello World
- Étape 5 : Créez un package pour votre action en saisissant un nom unique dans le champ Nom du package
- Étape 6 : Sélectionnez un temps d'exécution pour votre action. Vous pouvez prévisualiser le code del 'action type dans chaque moteur d'exécution disponible avant de déployer le modèle
- Étape 7 : Cliquez sur Déployer. Vous avez créé une action. Bravo !
- Étape 8 : Exécutez l'action en cliquant sur Invoke. L'appel d'une action exécute manuellement la logique applicative définie par l'action. Dans le panneau Activations, vous pouvez voir le message d'accueil "Hello stranger !" produit par l'action
- Étape 9 : Facultatif: Cliquez sur Modifier l'entrée pour modifier l'action ou essayer la vôtre
- Étape 10 : C'EST TOUT ! Pour supprimer cette action, cliquez sur le menu de débordement et sélectionnez Supprimer l'action
Voici comment fonctionne IBM Cloud™ Functions d'un point de vue technique.
Cloud Functions est basé sur OpenWhisk, un projet open source qui combine des composants tels que NGINX, Kafka, Docker et CouchDB pour former un service de programmation événementielle sans serveur.(Source)
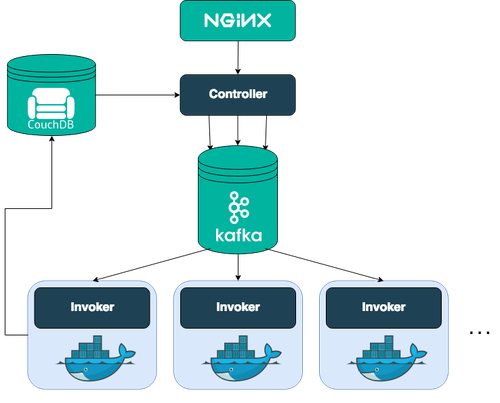
Le premier point d'entrée dans le système passe par NGINX, un serveur HTTP et reverse proxy. NGINX est utilisé pour la terminaison SSL et la transmission des appels HTTP appropriés. NGINX transmet la demande HTTP au contrôleur, le composant suivant sur le chemin d'OpenWhisk. Le contrôleur est une implémentation en Scala de l'API REST actuelle (basée sur Akka et Spray). En tant que tel, le contrôleur sert d'interface pour tout ce que vous voulez faire, y compris les demandes de création, de récupération, de mise à jour et de suppression de vos entités dans OpenWhisk et l'invocation d'actions. Le contrôleur vérifie maintenant qui vous êtes (Authentification) et si vous avez les autorisations requises pour faire ce que vous voulez faire avec cette entité (Autorisation). Les informations d'identification incluses dans la requête sont vérifiées dans la base de données des sujets d'une instance CouchDB. Une fois que le contrôleur a déterminé que vous êtes authentifié et autorisé à invoquer l'action, il charge l'action depuis la base de données des sujets dans CouchDB. L'équilibreur de charge, sachant quels Invokers sont disponibles, choisit l'un d'entre eux pour invoquer l'action que vous avez demandée. Le contrôleur et l'Invoker communiquent uniquement par le biais de messages qui sont mis en mémoire tampon et conservés par Kafka. Kafka libère le contrôleur et l'Invoker de la charge de la mise en mémoire tampon, tout en veillant à ce que les messages ne soient pas perdus en cas de panne du système. Pour exécuter les actions de manière isolée et sûre, Docker est utilisé pour mettre en place un environnement auto-encapsulé (appelé conteneur) pour chaque action invoquée. Une fois le conteneur créé, le code est injecté, puis exécuté avec les paramètres qui lui ont été passés. Lorsque les résultats sont renvoyés, le conteneur est détruit. Des optimisations des performances peuvent être effectuées à ce stade pour réduire les besoins de maintenance et permettre des temps de réponse faibles. Une fois le résultat obtenu par l'Invoker, il est stocké dans la base de données whisks en tant qu'activation sous l'ID d'activation attribué. La base de données whisks vit dans CouchDB.
Avantages et inconvénients des fonctions sans serveur d'IBM
En général, les IBM Cloud™ Functions sont utiles pour les petites tâches dans les applications mobiles avec des appels non continus. Les avantages ici sont l'évolutivité, le déclenchement facile et la validation des fichiers. Les IBM Cloud™ Functions conviennent notamment aux entreprises dont les processus sont compacts.
Libelle IT Group mise également sur les avantages du Cloud et vous propose différentes solutions. Utilisez dès maintenant les éditions Cloud de Libelle DataMasking (AWS / Microsoft Azure), Libelle SystemCopy (AWS / Microsoft Azure) ou Libelle CloudShadow (IBM Cloud).
Article recommandé
Tous les articles du blog